



一年多前,Cursor还是林鸣最常用的编程软件之一。
他是互联网大厂里负责Agent落地的工程师。那时候,他用AI写代码,主要让它补几行或者改个参数。在这个软件里,大模型塞进编辑器,他可以随时调用。
现在,林鸣已经很久没有打开Cursor了,日常用得更多的,是Claude Code、Codex,以及公司自研的AI编程工具。
这不只是工具的变化。如果说用Cursor的时候,AI更像一个副驾,程序员还坐在驾驶位上;那么到了Claude Code和Codex,模型被直接接进了研发流程。给它一个任务,它可以自己拆需求、读代码、调用工具、跑测试,并最终交付。
也就是说,林鸣可以把一整块工作都交出去了。但代价是,token的消耗也上去了。
过去,公司给工程师的额度几乎不限量,后来额度收紧,林鸣干脆自己订阅了好几款工具,身边像他一样的同事很多。
当一个开发者愿意自掏腰包,背后是一个已经跑出来的市场。
Anthropic是最早接住这个市场的AI公司。它虽然没有ChatGPT那样的C端流量,却靠Claude Code讲出了一个更容易算清账本的故事——开发者愿意付费,企业愿意采购。如今,它的用户量虽远远不及OpenAI,但估值已经反超,接近万亿美元。
承压的OpenAI也在调整重心。ChatGPT仍然是最大入口,但Codex的位置越来越重要。据报道,Codex半年周活增长逾7倍,目前已经突破500万。
国内的智谱是另一种样本。
其最新模型GLM5.2的软件工程能力逼近Claude Opus 4.8,Coding Plan的价格却只有Claude的七分之一。这家2025年营收仅7.24亿元、净亏损却高达47.18亿元的公司,市值一度突破万亿港元。市场买单的显然不是眼下的财报,而是“中国版Anthropic”的预期。
比起继续追用户规模,找到愿意持续付费的开发者和企业,正在变得更重要,这是2026年大模型商业化的分水岭。
字节现在也在靠近这条路。
其最新发布的豆包2.1 Pro,补上了Coding和Agent能力。在现场演示和评测中,火山引擎反复拿自己和Claude Opus等模型对标。种种迹象表明,字节不再只是追求更多用户打开豆包,而是开始瞄准开发者、Agent和真实工作流。
对于一家长期信奉“模型即产品”,最擅长用C端流量滚出飞轮的公司来说,这个转身本身就代表了一种信号:免费聊天能带来热度,却很难撑起一门生意。
01.豆包掉头:一半是诱惑,一半是成本
豆包的掉头并非突然发生。
据多家媒体报道,字节高层到访Anthropic后,内部启动AI资源重整,把更多资源从豆包这类大众产品,挪向企业服务和编程模型。为此,大模型数据审核团队从约1500人扩到3000多人,专门为编程模型清洗数据。火山引擎MaaS还被定下收入翻10倍的目标。
这次,它不仅仅是发布了一个更会写代码的新模型,是在组织和资源层面,把AI商业化的重心往B端推。
字节转向B端,动力来自两个方向。
向外看,企业市场已经开始为AI能力付费;向内看,持续高企的算力支出,也迫使每家公司尽快找到一条能够自我造血的路。
先看收入端。
短短两年,AI coding已从程序员尝鲜的玩具,变成企业软件工程的一部分。Stack Overflow 2025年开发者调查显示,84%的受访者已在开发流程中使用或计划使用AI工具,较前一年的76%持续攀升;其中近半数(47.1%)开发者每天都在使用AI编程。Gartner则预测,到2028年,90%的企业软件工程师将使用AI代码助手,而2024年初这一比例还不到14%。

图源 / unsplash
AI coding的商业价值,体现在两个层面。
一层是开发者的付费意愿。过去,AI编程工具只是几美元一个月的插件。现在,主流产品普遍采用订阅加用量的模式,个人版每月十几到几十美元,高强度Agent版本可以到100美元以上。
一位开发者打趣说,过去担心的是“别让AI取代我”,现在变成了“别把AI从我手里夺走”。
另一层是企业的买单意愿。企业按席位、按token、按合同付费。只要工具能进入研发流程,就有机会变成可预测的现金流。
Anthropic的收入曲线,更是让行业看到了这个市场的潜力。去年5月才发布的Claude Code,到2026年2月,年化收入已经达到了25亿美元。其中,超过一半来自企业客户,年支出100万美元以上的大客户,两个月内从500多家增至1000多家。整个公司的年化收入也随之水涨船高,从2月的140亿美元,一路攀升至5月的470亿美元以上。
再来看成本端。
互联网时代生意逻辑是“先做规模、再谈变现”。用户够多、停留够久,靠着广告、电商、会员,总能赚到钱。
但现在这一套不灵了。AI应用不是信息流,每一次提问、生成,背后都是真实烧掉的算力。甚至,用户越多,成本越高。
豆包正承受着这种压力。据《晚点LatePost》报道,每天2亿多人使用的豆包,日收入不足百万元,且主要来自电商佣金。但今年5月,豆包每天消耗的算力成本达数千万元——文字聊天尚不算贵,而推理、图片识别、语音聊天、视频聊天等多模态功能的算力成本,是纯文本交互的几倍甚至几十倍。
支出压力也体现在企业内部的token使用上。
林鸣表示,他所在的公司一开始给的额度几乎不限量,是因为管理层看到AI能力强,但不清楚到底多强、能给企业带来什么,只能让大家先用起来看效果。可用了一阵,发现收益并没有成倍增长,于是公司开始控制成本。
字节技术副总裁洪定坤在一次公开演讲中,也提到过类似落差。字节专做AI coding的TRAE团队,90%的代码已经由AI写出,但人均需求吞吐率只提升了60%。
洪定坤认为,问题出在写代码之后。字节做过一组实验,在不同模型和框架下,AI生成代码的功能正确率普遍超过80%,但到了UI、可靠性、可维护性这些真正决定能否上线的维度,分数却只有40到60分。
算力烧掉了,可交付的产出却没跟上。这个差距,正是大厂转向B端时必须先解的题。只有把那些40到60分的半成品打磨成可交付的产出,烧掉的每一分算力才算真正转化成了生产力。
02.字节的优势,也可能是包袱
豆包的这次转向,是字节整体AI战略的一部分。
字节的AI业务大致有四条主线:世界模型、视频模型、Coding与Agent、豆包商业化。现在拨动的,正是后两条。
Coding与Agent负责打开企业入口,豆包商业化负责回答另一个问题:庞大的C端流量怎么换成收入。
AI coding这条赛道,目前已经分化成三个层级。面向程序员日常开发的Copilot式插件、重做开发环境的AI IDE,以及试图接管整个任务流程的Coding Agent。
字节的布局恰好覆盖了这三层。前端用TRAE和插件抢占开发者入口,中间层以CLI和企业版切入研发流程,底层由火山方舟和豆包模型提供算力与模型供给。6月23日发布的豆包2.1 Pro,则将重心明确押在了Coding和Agent上,官方称其在多项测试中接近甚至追平GPT-5.5和Claude Opus 4.7。
字节这套打法的底气,来自于其已经验证过的企业服务能力。
火山引擎在B端服务企业多年,握有从云、模型调用、MaaS到交付的完整链条。飞书沉淀了大量企业客户和办公协同场景。Seedance则已经跑通了“把模型能力卖给企业”的模式,年化收入约143亿元,毛利率约70%,单月进账几乎覆盖豆包的算力成本。
字节真正想做的,是比模型更底层的基建。洪定坤在演讲中提到一个词——Harness。它指向的是一套涵盖上下文工程、架构约束、团队知识沉淀、技术债梳理,以及测试与交付流程的系统。他的判断是,只有把这些齿轮重新咬合,AI coding才能从生成代码跨越到完成需求。
铺开这套基建,字节仍然沿用了低价策略。
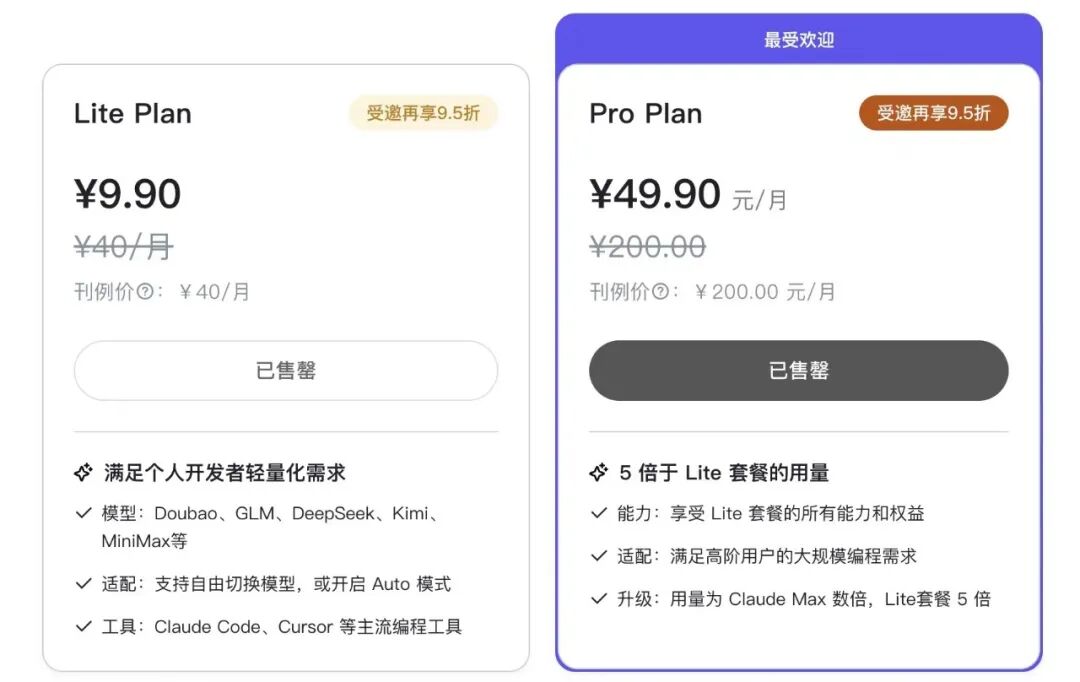
根据豆包Coding Plan定价,最低首月仅需9.9元,Lite套餐后续40元/月,Pro套餐后续200元/月。相比之下,海外主流AI编程工具每月订阅普遍20美元起步,高强度Agent版本可达100美元以上——字节给出的入门价格,几乎是“尝鲜无负担”。
API侧的打法更为直接。Doubao-Seed-Code按上下文长度分层计费,输入价格每百万tokens最低1.2元,输出价格最低8元;火山引擎称,配合缓存后综合使用成本比行业平均低62.7%。
Coding Plan还支持Claude Code、Cursor、Cline、Codex CLI等主流开发环境,意味着开发者不需要迁移工作流,只要把底层模型换掉,就能把原本花在Claude和OpenAI上的部分用量切到豆包。这相当于用价格换切量,用兼容换迁移成本。
对比Claude Code和Codex,字节选择了一个“低价+产品化+生态打包”的组合,把价格压下来、把接入做顺、把工具做轻,让开发者低成本试用,再争取进入工作流。
这正是字节在C端最熟练的打法,也是它眼下最大的优势。火山、飞书、豆包模型构成的底盘,是智谱、DeepSeek们短期内复制不了的;低价策略和兼容主流开发环境的设计,也几乎是为快速渗透量身打造的。
但B端和C端不同。C端可以靠低价、补贴和快速试错拉动增长,B端相反,程序员可以为便宜来试用,但能不能长期留下,看的是产品能不能稳定接住复杂任务、能不能在出问题时给出及时的响应。字节最擅长的快速试错文化,恰恰是B端最警惕的东西。
谷歌是一个值得参考的对照。
它手握Google Cloud、Android、Chrome、Workspace,几乎拥有全球最强的开发者生态,也早早推出了Gemini Code Assist和Gemini CLI。论入口、论生态、论企业客户,谷歌并不缺牌;论价格,它也不算激进——Gemini Code Assist Standard年付折合每人每月仅19美元。
但至少到目前为止,开发者心智并没有自然流向谷歌。这说明,在AI coding这门生意里,生态和价格都只是入场券,真正难的,是产品体验、模型能力、任务完成率和开发者信任。
字节靠低价和生态切入,目前也只是拿到了留在牌桌上的资格。
03.贴身肉搏才刚刚开始
在林鸣这样的重度用户心里,模型早已排好座次。
第一梯队是Claude和ChatGPT,第二梯队是智谱、Kimi、DeepSeek,其余大多滑入第三梯队。他算过一笔账,自己花在大模型上的钱,九成给了第一梯队,剩下的大多投向DeepSeek。道理很简单,Claude和Codex负责最难的任务,DeepSeek便宜、耐烧,适合日常的简单活儿。
“这就像游戏里的外挂,”他打了个比方,“最难的任务当然用最强的武器,简单的才交给性价比更高的模型。”
这种“谁好用就用谁”的态度,在开发者中相当普遍。
一位科技博主的说法更直接,AI时代,用户没有忠诚度,换一个AI工具很多时候只是换个输入框。各家辛苦争来的开发者,随时可能因为别家更好用、更便宜、更稳定而流走。
更麻烦的是,模型之间拉开差距正变得越来越难。
林鸣能明显感觉到,模型还在进步,但进步速度已经不如之前,各个模型之间的差距也更小了。
这类判断也出现在很多公开的讨论里。a16z创始人Marc Andreessen近期发文称,多位从业者认为GLM-5.2可能是第一个在多数任务上匹敌、甚至超越美国头部实验室公开模型的中国模型。他将此视为一个关键节点,认为大模型的能力格局正从少数美国实验室主导走向多极化。
当能力差距缩小,各家的定价策略就成为关键。如果算不好账,可能会伤到自家账本。
目前Coding的付费结构主要包括两部分,个人开发者买订阅,企业客户走API、席位费或合同;前者负责扩大规模、养成付费习惯;后者才是利润的大头。
就拿Claude的定价策略来说,个人订阅分为20美元、100美元和200美元三档,虽然不同档位有相应的用量上限,但整体上收入仍受限于月费模式。API则按token计费,以常用于Coding的Sonnet模型为例,输入和输出价格分别为每百万tokens3美元和15美元,更高端的Opus模型则分别为5美元和25美元。在高强度、全天候的Agent任务等极端使用场景下,企业的API支出可能达到个人订阅的数十倍。

图源 / Claude官网截图
Agent一旦进入真实工作流,算力成本持续攀升,订阅收入却有上限,厂商只能靠限额、峰值扣减来兜底。智谱就吃过苦头。其Coding Plan一度卖得太好,不得不限量发售,高峰期按更高倍率扣减额度。
即便是Anthropic和OpenAI,也得小心维持这道平衡。它们一边要让开发者高频使用、形成黏性,一边用精细的限额管理重度用户。Claude的Pro和Max分档限容,Codex的调用计入专门的额度。订阅看似是固定价格,背后却是一本被严格计量的算力账。
这条赛道,还在不断涌入新玩家。
仅6月下旬,DeepSeek就高调扩招、筹建对标Claude Code的团队,Kimi也把企业业务摆到了更重要的位置。
而越往深处看,赛道越清晰地分成两条路线。
一条是Anthropic和OpenAI代表的专有模型高端路线。它们卖的不是一个便宜模型,而是企业里的AI员工。它们的底牌,是模型能力、产品心智和企业信任。
另一条是更低价、更开放的模型底座路线,DeepSeek、智谱、Kimi、MiniMax扎堆于此。它们想成为别人AI员工背后的模型底座,抢的是API调用、工具集成和私有化部署的份额。
DeepSeek以开源和低价切入,智谱更靠近B端,把模型、Agent、私有化和政企服务打包出售;Kimi和MiniMax则用长上下文、多模态和性价比争夺开发者。
字节恰好卡在两条路线的中间。
它想要的,是闭源高端路线的终点——一套能稳定交付、能写进企业合同、能嵌进工作流的Agent系统。但它选择的入口,却更接近低价路线,压低价格的同时,用兼容性把开发者原本花在Claude和OpenAI上的用量切过来。
这种打法,可能让它两头通吃,也可能让它两头都不够硬。因为,论开发者心智,它一时还难超过Claude Code和Codex;论极致性价比,又得直面DeepSeek、Kimi、智谱的持续挤压。
模型还在变强,差距却在变小。这场竞争最终拼的,是谁能在算力账本上撑得更久。谁能跑出来还没有答案,但接下来一定是一场谁都不敢松手的贴身肉搏。
*题图来源于豆包微信公众号截图。林鸣为化名。